Understanding Cyclomatic Complexity
Introduction
This blog looks at cyclomatic complexity in the kuadrant project. Cyclomatic complexity is a metric design to indicate the complexity of an application. In this post we recap the research outlined in the paper of the same name, the paper can be found here. The main goal is to learn what cyclomatic complexity is and how best to apply it to a project.
Understanding Cyclomatic Complexity
Cyclomatic complexity is a measurement created from the control flow of an application. The simplest understanding of how to calculate this metric is every time the function makes a choice, 1 gets added to complexity score and a function has a base level of complexity of one.
Code readability has no effect on the complexity score and that means the style of a language or the styled opinions of a team will not affect the score. Scores across different language should not be compared with each other, as some language features will shift the score between languages. For example Golang has errors as values while Python uses a try catch block. While those approaches try to achieve the same results it can affect the cyclomatic complexity.
Classifying Cyclomatic Complexity
The metric itself is a single number but when looking a project it is better when the metric is bucketed into categories. The bucket classification used is from radon.readthedocs.io, it gives a good range at both ends of the spectrum. These classifications are in the table below.
| CC Score | Rank | Risk |
|---|---|---|
| 1 - 5 | A | Low - simple block |
| 6 - 10 | B | Low - well-structured and stable block |
| 11 - 20 | C | Moderate - slightly complex block |
| 21 - 30 | D | More than moderate - more complex block |
| 31 - 40 | E | High - complex block, alarming |
| 40+ | F | Very high - error-prone, unstable block |
Data Collection and Analysis
The analysis was done on all public repositories in the Kuadrant GitHub organization using Jupyter Notebooks, these notebooks can be found here. A number of steps where taken to clean up the data including the exclusion of vendored or generated code. The temporal data points were base of the merge commits or standard commit depending on the project.
Diving Into The Complexity
Kurdrant Project
One of the very first stand out points when looking at the graph of the cyclomatic complexity over time for the kuadrant project as a whole nearly doubles in complexity each year. This is expected as the project is very much in its growth stage. What should be highlighted is any new user wishing to contribute will have a far greater learning curve than someone that joined the project the year before. The next point is from the shear scale of Rank A functions in the project. Remember Rank A are simple blocks. While these are not hard to understand, new contributors will need to understand how to tie all these functions together. Low ranked functions add a mental complexity on the developer.
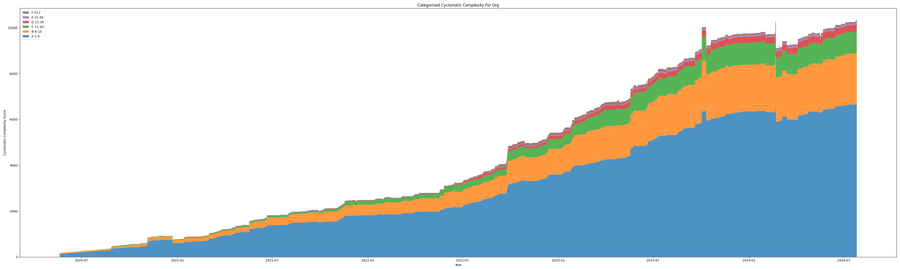
Projects Evolving Over Time
The wasm shim is a very good example of the cyclomatic complexity of a project evolving over time. The graph below shows how in the earlier stages of the project there was some very complex functions with bands of functions with a Rank D and Rank E. Over time with refactoring these complex blocks where rewritten to give simpler code blocks but also didn't drastically reduce the over all complexity of the project.
This gives reason to believe CICD checks based on cyclomatic complexity may be a hindrance and harm productivity on projects that have a good culture of being able to refactor complex code at later dates. This pattern of highly complex code being added to a project and then later refactored out can be seen within all the kuadrant projects.
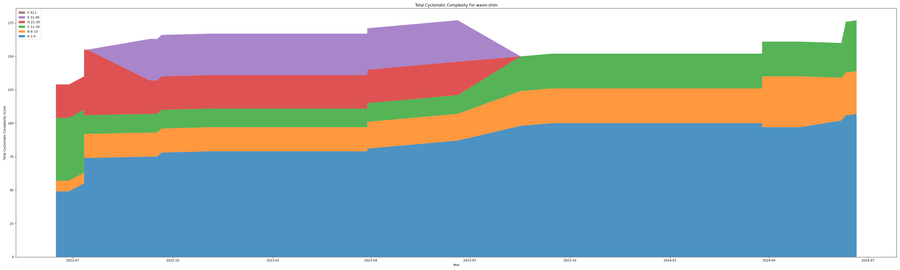
Change Of Personnel
The beliefs of a team can effect how the cyclomatic complexity is grouped into the different ranks. In limitador around July 2022, there was a new lead maintainer added to the project. With talking to this maintainer, they have a strong belief that APIs should be simplified for consumers of the API at the expense of the library maintainers. This would mean if the consumers normal calls function A and function B at the same time those function should be combined into a function AB. This leads to higher complexity in functions but simpler interfaces for consumers.
While showing that the cyclomatic complexity is as much affected by team culture and design philosophy as language and project complexity. Also, that over time as teams change so will the design philosophy which should not be seen as inherently a bad thing.
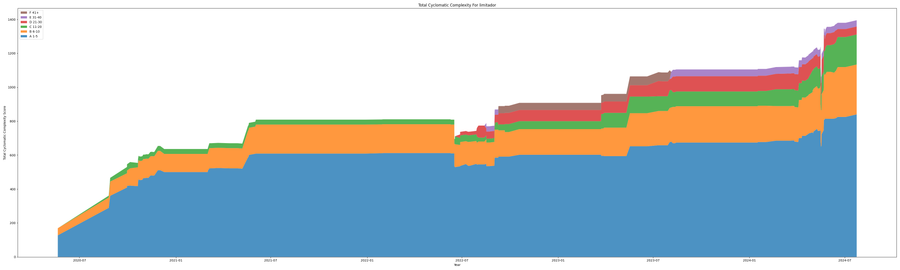
Runtimes And Tooling
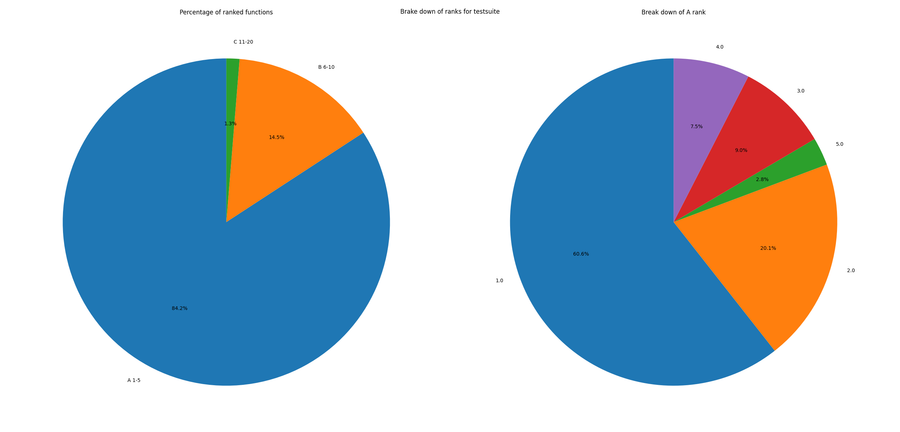
The testsuite repository showed an interesting flaw with using cyclomatic complexity and the surrounding tooling. Nearly 90% of all functions are in the rank A grouping. While it was expected the repository would have a higher number in this group because of some of the Python language features. The high number of rank A scoring functions was due to the use of the assert keyword. As this was a test suite it made use of the Pytest framework which overrides the build in assert keyword and the created test make heavy use of the assert keyword. In the Python language the execution of the asserts can be turned off, because of this the tool used to scan and calculate the cyclomatic complexity score of a function did not count assert as part of the complexity. Meaning the scores for the testsuite were underreported.
The takeaway from this is how there you need to have an understanding of the language features, frameworks being used and calculation rules of the scan tools. As when the three are combined the results maybe misleading.
Historical Events
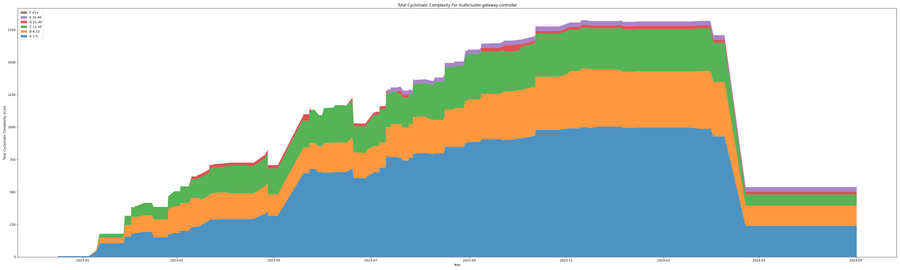
Apart from the normal growth of a project, historical events can be detected. This can be events where large features are added or removed. These events normally show as jumps in the graphs over being a spike in the graph. No project shows a better example of this than the multicluster-gateway-controller, as seen in the below graph. This relates to the removal of two controllers from the project. These controllers were refactored into the kuadrant-operator project.
In this case, it was a massive change that is easy to spot. In every project, you can see a number of jumps that would be the result of new features being merged into the project. An interesting way to look at these jumps is from the agile methodology and continuous delivery. If these processes are working correctly there should be limited large upwards jumps, as code should always add in small chunks.
Using the cyclomatic complexity metric
The metric should be used as a guide to aid in decision-making but should not be tracked as a sign of code quality.
Guide for testing
The cyclomatic complexity metric can be used as a guide to the minimum number of unit test that should be written for a give function. This make it easy for a developer to hit more of the logic branches within the code under test. Unlike code coverage, the aim is to write more variety in the test. While at the same time will not expect an excess of tests to cover every possible iteration of the function.
As a guide it is still up to the developer to write good meaningful tests. The cyclomatic complexity like code coverage will not point out the edge case in the software. That is still up to the developer to understand.
Aiding system design
Using cyclomatic complexity to aid in system design will depend on the school of thought around what scores are acceptable. Followers of "Clean Code" will believe functions should be short with minimal logic. This means the cyclomatic complexity will show areas that need refactoring to lower the metric for those functions. But if the belief is interfaces should be deep and not shallow, then the metric can show you functions that doing very little but require developers to know of their existence.
My personal opinion is functions should try to be in Rank B (6-10 range). This greatly reduce the number of APIs that a developer is required to learn while at the same time keeping the functions "understandable". Yes there can be functions that fall outside this range on both sides. The reconcile function in an operator tends to have many function calls with error checking, these function have higher cyclomatic complexity because of the error checking.
Missing Information
Looking into cyclomatic complexity and how to use the metric, it becomes clear there is information that would aid in its usefulness. The idea of code churn would highlight functions that have been updated regularly. This can indicate that the function is overly complex and people do not understand the function enough to create valid updates the first time around.
Knowing the number of calls to a function could show premature abstractions. On low complexity functions this leads to a cognitive load on the programmers as they are required to have a deeper knowledge of the functions within a code base. This is especially true for new contributors joining a project.
Conclusion
The conclusion of this research into cyclomatic complexity is as follows. While the cyclomatic complexity scores can show how large a project is, it will not say anything about how well it is designed. It is a good metric for identifying areas within a code base that maybe too complex, and should have a refactor done. The inverse is also true, it can identify areas that are overly simple requiring developers to hold more information in their heads.
Begin able to calculate the cyclomatic complexity manually in your head can be useful as a guide to how many test cases for a function should be created. The test cases still need to be meaningful, and not created to just please some metric on a dashboard.
Tracking the metric over time is worthless, as the project grows, so does the cyclomatic complexity and therefore the metric. Where the over time metric can be used is a reminder to existing developers of how much more complex the project is of new developer's starting. The onboard time for a new developer will take longer, and any existing developers may require more patience with the new developer. Tracking the Ranks proportional over time may have some benefit in identifying when a project is starting to slip and get "untidy".
Overall, it is a nice metric, just like code coverage, it is a bit meaningless but can help drive decisions on a case by case bases. For public facing APIs, it can help identify areas that many be too broad requiring a developer to hold more context than is required to use the API.